
Introduction¶
Twitter is one of the largest social media platforms, with roughly 330 million active users. All posts on Twitter contain 280 characters or less, and users can post images, videos as well as gifs. Furthermore, users can share, reply, and react to other tweets. Each user's feed is unique, as the information that a user sees on their Twitter feed consists of on the activity of the users that they are following (liked posts, retweets, replies, and full posts). Due to the personalized nature of Twitter feeds, one might expect that Twitter is a hotbed for community formation.
In this tutorial, we will focus on community analysis of Twitter data, specifically the 'bio' portion of Twitter profiles. Bios are short text segments, and can contain anything a person would like. We see data such as professions, political affiliations, interests, education, and more. Therefore, we want to identify community using similarity between user bios.
Getting the Data¶
This section will describe the process that we took to collect and parse the data. To get started, we needed access to the Twitter API, which one of our group members already had. We used the Twitter Decahose to collect 20gb of a random 10% sample of all public twitter activity that took place on November 11, 2019. If you do not have access to the Twitter Decahose, there are other ways to get access to Twitter data, such a signing up for the 1% Twitter activity sample API and using Tweepy.
The Twitter API's activity stream provides an HTTP stream of utf-8 encoded JSON objects, each representing a new activity on twitter (post, retweet, reply, etc). The Twitter API recommends putting the json data in a first-in first-out queue, and having another process consume the queue as it comes in. This is because if there is a sudden spike in Twitter activity, it may overload a script that tried to process the data as it comes in. Using a FIFO queue provides flexibility in volume that your system can handle, and ensures you will not miss any activity from the stream. In accordance with this, we will take each tweet JSON and add it to a queue stored on the disk.
Below is an abbreviated version of the code that we used to put the tweet data into an on-disk queue using a Python package persist-queue.
import persistqueue
q = persistqueue.Queue("./tweetqueue")
# For each tweet in the stream
# q.put(tweet)
Each element of the queue will look something like the json shown below. For this analysis, we are using the data in the 'actor' object. The actor is the profile that initiated the activity, so wether the activity is a regular tweet, a share, or a quote tweet, we will still get the profile that initiated it's profile information. The 'summary' object of the 'actor' object is the user's bio.
{ "id":"tag:search.twitter.com,2005:1193954984645287936", "objectType":"activity", "verb":"post", "postedTime":"2019-11-11T18:13:45.000Z", "generator":{ "displayName":"Twitter for iPhone", "link":"http:\/\/twitter.com\/download\/iphone" }, "provider":{ }, "link":"http:\/\/twitter.com\/bocasfenti\/statuses\/1193954984645287936", "body":"@ArianaGrande i love u sm", "display_text_range":[ ], "actor":{ "objectType":"person", "id":"id:twitter.com:1124138035619205120", "link":"http:\/\/www.twitter.com\/bocasfenti", "displayName":"\ud835\udc4e\ud835\udc5a\ud835\udc4e\ud835\udc5b\ud835\udc51\ud835\udc4e \ud835\udc59\ud835\udc5c\ud835\udc63\ud835\udc52\ud835\udc60 \ud835\udc4e\ud835\udc5f\ud835\udc56", "postedTime":"2019-05-03T02:26:07.960Z", "image":"https:\/\/pbs.twimg.com\/profile_images\/1193663233619574784\/ecbLc_3M_normal.jpg", "summary":"\ud835\udc26\ud835\udc1e\ud835\udc2b\ud835\udc2b\ud835\udc32 \ud835\udc1c\ud835\udc21\ud835\udc2b\ud835\udc22\ud835\udc2c\ud835\udc2d\ud835\udc26\ud835\udc1a\ud835\udc2c, \ud835\udc21\ud835\udc1e\ud835\udc2b\ud835\udc1e \ud835\udc22 \ud835\udc1a\ud835\udc26, \ud835\udc1b\ud835\udc28\ud835\udc32 @arianagrande", "friendsCount":1812, "followersCount":1737, "listedCount":19, "statusesCount":2131, "twitterTimeZone":null, "verified":false, "utcOffset":null, "preferredUsername":"bocasfenti", "languages":[ ], "links":[ ], "location":{ }, "favoritesCount":5062 }, "object":{ "objectType":"note", "id":"object:search.twitter.com,2005:1193954984645287936", "summary":"@ArianaGrande i love u sm", "link":"http:\/\/twitter.com\/bocasfenti\/statuses\/1193954984645287936", "postedTime":"2019-11-11T18:13:45.000Z" }, "inReplyTo":{ }, "favoritesCount":0, "twitter_entities":{ "hashtags":[ ], "urls":[ ], "user_mentions":[ { "screen_name":"ArianaGrande", "name":"Ariana Grande", "id":34507480, "id_str":"34507480", "indices":[ 0, 13 ] } ], "symbols":[ ] }, "twitter_lang":"en", "retweetCount":0, "twitter_filter_level":"low" }
Once we have our json object queue, the next step is to get to a point where we can create a Pandas dataframe. If you are unfamilar with Pandas, we suggest following this turorial first, until you feel comfortable working with Pandas. To access the queue, we popped each tweet off the queue, parsed out the bio information, and put it into a Pandas dataframe. For this project, we were mainly focused on collecting data from users' twitter bios, so we only selected features related to that and the user themselves (username, bio, follower count, etc).
import json
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# Initialize dataframe
colNames = ("username", "displayName", "bio", "followers", "following", "status_ct", "objType", "verified", "acc_id", "numFavs")
df = pd.DataFrame(columns = colNames)
# Get the queue
q = persistqueue.Queue("./../fakeq")
# Consume the data from the queue and add it to dataframe
count = 0
# We left the sample size at 500 here, but when we ran this script
# we set sample size to 200,000
sampleSize = 500
while (count < sampleSize):
try:
# Parse tweet
tweet = json.loads(q.get().decode('utf8'))
#Skip tweets that are not in english
if tweet['twitter_lang'] != "en":
continue
# Add tweet data to dataframe
act = tweet['actor']
bio = act['summary']
typePerson = act['objectType']
uID = act['id'][15:]
dispN = act['displayName']
followin = act['friendsCount']
flrs = act['followersCount']
numTweets = act['statusesCount']
ver = act['verified']
un = act['preferredUsername']
favCt = act['favoritesCount']
# make sure bio exists
if bio != None:
bioInfo = [(un, dispN, bio, flrs, followin, numTweets, typePerson, ver, uID, favCt)]
df_temp = pd.DataFrame(bioInfo, columns = colNames)
df = df.append(df_temp)
count += 1
except Exception as e:
print(str(e))
# Give each row a unique index
df.index = range(df.shape[0])
Now our dataframe contains information about twitter users' profiles.
df.head()
Twitter Bio Natural Language Analysis ¶
Now that we have our dataframe, we can start doing some exploratory data analysis. We will the NLTK library to do some analysis on twitter bios. For more reading about NLTK, see this link
Let's do some preliminary Natural Language Processing¶
Our first step is to tokenize the data. Before we do so, we want to identify some characters/words that we want to filter out. NLTK comes with a downloadable set of english stop words, such as 'we', 'before', and others. We decided to remove all stopwords from user bios, except for any gender pronouns from the set, as information on whether or not a user identifies as male/female/other is useful to us.
import nltk
from nltk.corpus import stopwords
# Modify stopwords set
stopW = set(stopwords.words('english'))
stopW.remove("they")
stopW.remove("he")
stopW.remove("them")
stopW.remove("she")
stopW.remove("him")
stopW.remove("hers")
stopW.remove("his")
stopW.remove("her")
stopW = stopW.union(set([",", ".","n't", ";", '"', '”',
"'",
'“', "@", "#", ":", "'m", "''", "!", "&", "(", ")", "...", "’", "-", "•", "'s", "http","https", "[", "]", "?"]))
# Tokenize twitter bios
df["bio"] = df['bio'].apply(lambda x: x.lower().replace("/", " ").replace("\\", " ").replace("|", " "))
tokenSeries = df['bio'].apply(lambda x: nltk.word_tokenize(x))
tokenSeries.head(2)
Next, we will create a dictionary that relates each word with its total number of occurances across bios. We will then use this dictionary to get a list of the top 1500 occuring words in the whole corpus. This list will be used as the columns for our term frequency table
bioWords = {}
# go through each tokenized bio
for myList in tokenSeries:
for tok in myList:
if tok not in stopW:
if tok not in bioWords:
bioWords[tok] = 1
else:
bioWords[tok] += 1
# Converts entries in the dictionary into tuples, and sorts them by occurences.
tupList = []
for key in bioWords.keys():
tupList.append((key, bioWords[key]))
tupSorted = sorted(tupList, key=lambda item: item[1], reverse=True)
# Get the top 1500 words based on occurance. These will be used for our columns in the
# term frequency table
topBioWords = [k[0] for k in tupSorted[:1500]]
Term Frequency Analysis¶
Now we'll create a term freqency matrix using the token series and the top bio words. This kind of matrix will allow us to analyze similarity between bios.
# Initialize an empty matrix
tfDf = pd.DataFrame(index=df['bio'], columns=topBioWords)
bio_idx = pd.DataFrame()
bio_idx["bio"] = df["bio"]
bio_idx["tokens"] = tokenSeries
# Fill the matrix
for row in bio_idx.iterrows():
tRow = row[1]
for tok in tRow['tokens']:
if tok in topBioWords:
tfDf.at[tRow['bio'], tok] = True
tfDf = tfDf.fillna(False)
tfDf = tfDf*1
# Print the first 2 entries of our term frequency matrix
tfDf.head(2)
We now have a term frequency matrix that we can use to perform some analysis. However, we want to normalize this data. To do so, we can convert this into a TF-IDF matrix to weight each word by its frequency across all documents in the corpus.
Note:¶
Up until this point we have been using a small sample of the full dataset that we want to use. Doing certain operations on the full 200,000 samples takes tens of minutes. As to not repeat this computation every time we start our notebook, we decided to store our results in a binary file that is stored on disk. Performing this process in Python is called pickling the data.
From this point on in the tutorial, we will be using the pickled results.
# Load in the pickled data
tfDf = pd.read_pickle("./../tfDf.pkl")
tfDf.head(5)
We have the term frequency table for all of our data. Next we want to create a one-row dataframe that contains the full count of the occurance for each of the top 1500 occuring words. We will use this count to normalize words by how much they appear overall.
totals = []
# Sums up the term frequencies
for k in tfDf.columns:
totals.append(tfDf[k].sum())
normDf = pd.DataFrame(data=[(totals)], columns=tfDf.columns)
normDf.head()
Now that we have our term frequency table, lets make a bar graph for the frequency of each word in the corpus. We will use every 50th word out of the 1500, ordered by their frequency.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# construct a dataframe that will allow us to graph frequencies as a bar plot.
normTransDf = normDf.transpose()
normTransDf["word"] = normTransDf.index
normTransDf["index"] = range(normTransDf.shape[0])
norm50df = normTransDf[normTransDf["index"] % 50 == 0]
plt.figure(figsize=(8,8))
sns.barplot(data=norm50df, x=norm50df[0], y = norm50df["word"], color="lightblue")
plt.show()

The bar plot above shows the frequency of common words in the corpus. To prevent from having 1500 rows, we plotted every 50th word. From the bar plot, we can see that the word 'love' occurs far more than the next 29 bars. After 'love', the frequency of each word tapers off rather quickly. Lets try to normalize this drop off by taking the log of the word frequency column
norm50df['log'] = np.log(norm50df[0])
plt.figure(figsize=(8,8))
sns.barplot(data=norm50df, x=norm50df['log'], y = norm50df["word"], color="lightblue")
plt.show()

TF and TF-IDF Analysis¶
We now have the TF score for the top 1500 most occuring words in the corpus. Using this, we can create some plots to find words that are closely related with each other. To start, we will create some word clouds to visualize the relationships between certain words. Since there are so many words, we decided to limit our community analysis to five key words that each represent a different community. The five communities that we chose are Trump2020, Bernie2020, Sports, Queer, and BTS (a K-pop group that is quite popular on twitter).
Lets create those word clouds.
%matplotlib inline
from wordcloud import WordCloud
import numpy as np
from PIL import Image
This function takes a word, computes the words that occur most frequently with that word in a user's bio, and plots a word cloud.
def makeWordWall(word):
plt.figure(figsize=(8,8))
sampleDf = tfDf[tfDf[word] > 0]
freqDict = {}
for col in sampleDf.columns:
freqDict[col] = sampleDf[col].sum()
freqList = []
for key in freqDict.keys():
freqList.append((key, freqDict[key]))
freqSorted = sorted(freqList, key=lambda item: item[1], reverse=True)
wordDict = {}
for tup in freqSorted[1:35]:
wordDict[tup[0]] = tup[1]
wc = WordCloud(background_color="white", max_words=100, width=500, height=500)
wc.generate_from_frequencies(wordDict)
# show
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
makeWordWall("trump2020")

As we can see in this cloud, words that are strongly associated to "Trump2020" are "maga", "kag" (keep america great), "conservative", "patriot", and more. One thing we found puzzling was the term "wwg1wga". After looking this up, we found that it stands for "when we go one we go all", and is closely associated with the right-wing conspiracy group known as Qanon. Another thing we noticed is that words associated with "Trump2020" are more related to the conservative movement, confirming our method of identifying communities, as Trump is a conservative candidate.
makeWordWall("bernie2020")

From this word cloud, we can see that the terms that are related to "Bernie2020" are "progressive", "socialist", "democratic","impeachtrump", and more. One thing we noticed about the words in this cloud is that they are not as large as the previous one, which indicates weaker relationships. Furthermore, we noticed that there are a number of words that are not related to the progressive movement such as "animal", "writer", "mother". This suggests that the community related to "Bernie2020" is not as tightly knit as the community for "Trump2020".
Now that we know how these word clouds convey information about their respective communities, we will forego analysis on the next three communities.
makeWordWall("sports")

makeWordWall("bts")

makeWordWall("queer")

Community Analysis with NetworkX ¶
Now that we have made our word clouds, we want to perform a more in-depth analysis on the communities that we have selected. To do this, we will use NetworkX to create graphs of the communities. We will start by defining a function that gets the edges for each community and formats them in a way that is compatible with NetworkX.
def get_edges(word, num_edges):
sampleDf = tfDf[tfDf[word] > 0]
freqDict = {}
for col in sampleDf.columns:
freqDict[col] = sampleDf[col].sum()
freqList = []
for key in freqDict.keys():
freqList.append((word, key, {'weight': freqDict[key]}))
freqSorted = sorted(freqList, key=lambda item: item[2]['weight'], reverse=True)
return freqSorted[1:num_edges]
The function get_edges takes a word and returns a list containing the top k edges connected to that word.
To test this function, we will create a graph between just two communites, "Trump2020" and "Bernie2020".
import networkx as nx
G = nx.Graph()
plt.figure(figsize=(15,15))
#G.add_nodes_from(tfDf.columns)
trump_edges = get_edges('trump2020', 100)
bernie_edges = get_edges('bernie2020', 100)
trump_nodes = map(lambda x: x[1], trump_edges)
bernie_nodes = map(lambda x: x[1], bernie_edges)
G.add_nodes_from(trump_nodes)
G.add_nodes_from(bernie_nodes)
G.add_edges_from(trump_edges)
G.add_edges_from(bernie_edges)
nx.draw(G, with_labels=True)
plt.show()

As we can see from the graph above, the Trump2020 and Bernie2020 communities are not extremely closely related. On the top left, we can see the "Trump2020" community, and on the bottom right we see the "Bernie2020" community. From this graph, we can see that the edges connected to "Bernie2020" are farther out than the edges connected to "Trump2020", confirming our assumption that the "Bernie2020" community is not as tightly knit. Furthermore, we can see that there are a few nodes that share a connection to both the Trump2020 and Bernie2020 communities. There are several nodes that are connecting both the communities such as mother, politics, support, wife, jesus. If we started removing edges, we would eventually see these two communities become disjoint from each other.
def get_edges2(word, num_edges):
sampleDf = tfDf[tfDf[word] > 0]
freqDict = {}
for col in sampleDf.columns:
freqDict[col] = sampleDf[col].sum()
freqList = []
for key in freqDict.keys():
freqList.append((word, key, {'weight': freqDict[key]}))
freqSorted = sorted(freqList, key=lambda item: item[2]['weight'], reverse=True)
return freqSorted[1:num_edges]
G = nx.Graph()
plt.figure(figsize=(15,15))
# Words selected by us to be graphed
wordList = ['trump2020', 'bernie2020', 'queer', 'bts', 'sports']
edges = []
for word in wordList:
edges += get_edges(word, 50)
nodes = map(lambda x: x[1], edges)
G.add_nodes_from(nodes)
G.add_edges_from(edges)
nx.draw(G, with_labels = True)
plt.show()

This is a graph using the basic TF on the 5 communities we listed in the word clouds and how they are connected. From this we can see that there are some communities are more connected such as "Queer"/"Bernie2020". Sports is related to every community. Next we will use a normalized TF matrix.
tfDf = tfDf.div(normDf.iloc[0])
G = nx.Graph()
plt.figure(figsize=(15,15))
# Words selected by us to be graphed
#wordList = tfDf.columns[:100]
wordList = ['trump2020', 'bernie2020', 'queer', 'bts', 'sports']
edges = []
for word in wordList:
edges += get_edges(word,50)
nodes = map(lambda x: x[1], edges)
G.add_nodes_from(nodes)
G.add_edges_from(edges)
nx.draw(G, with_labels = True)
plt.show()

This reduces variance among edge weights.
Now we will use the top 100 words, to try and get a larger set of communities.
G = nx.Graph()
plt.figure(figsize=(15,15))
# Words selected by us to be graphed
wordList = tfDf.columns[:100]
edges = []
for word in wordList:
edges += get_edges(word,30)
nodes = map(lambda x: x[1], edges)
G.add_nodes_from(nodes)
G.add_edges_from(edges)
nx.draw(G, with_labels = True)
plt.show()

It is not easy to identify community in this graph, due to many nodes and edges. Now we will use a library for detecting communities in a graph.
import community
communities = community.best_partition(G, partition=None, resolution=.5)
commDict = {}
for key in communities.keys():
if communities[key] not in commDict:
commDict[communities[key]] = [key]
else:
commDict[communities[key]] = commDict[communities[key]] + [key]
for key in commDict.keys():
print(str(key) + ": " +str(commDict[key]))
print()
Now we will choose a select few communities and visualize them.
def communityWall(wordList):
wc = WordCloud(background_color="white", max_words=100, width=500, height=500)
wc.generate(" ".join(wordList))
plt.figure(figsize=(8,8))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
commToShow = [4, 25, 9, 2, 13]
for key in commToShow:
communityWall(commDict[key])





nx.write_gexf(G, "communityP.gexf")
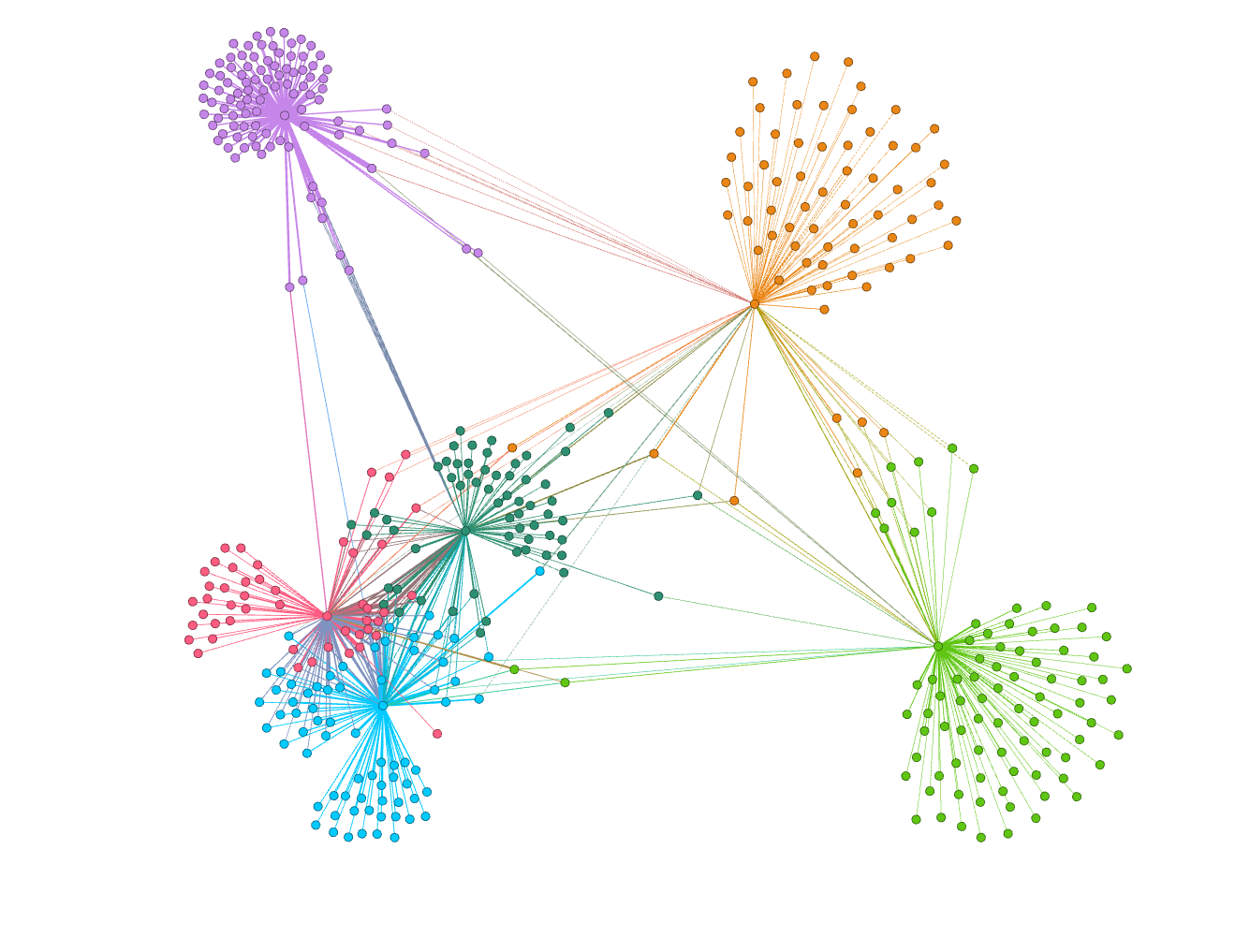
The command above created a .gexf file that we exported to Gephi to create this graph. Gephi can perform a physical simulation to visualize connections in a graph. This graph shows the 6 different communities "trump2020"(Red), "sports"(Purple), "bernie2020"(Orange), "2020"(Dark Green), "america"(Blue), and "queer"(Light Green). As you can see from the graph, "trump2020","2020", and "america" are closly related. "sports" is a tightly knit within itself, but has connections with all other communities.